| © 2022 Black Swan Telecom Journal | • | protecting and growing a robust communications business | • a service of | |
| |
| Email a colleague |
January 2021
TEOCO Brings Bottom Line Savings & Efficiency to Inter-Carrier Billing and Accounting with Machine Learning & Contract Scanning

The technology that telecoms provide — mobile communication, fast internet, cloud data centers, and everywhere connections — are the miracles of the modern world.
Yet network technology alone is not sufficient to make it all work. Another key enabler is the inter-carrier coordination and sharing that happens through trusted and efficient wholesale trading of facilities and services.
When it comes to sheer scale and variety of trading, no telecom wholesale market is bigger than the one in the U.S. — and that’s no surprise given that the U.S. is home to 24% of the world’s economic activity by GNP.
The foundation of robust wholesale sharing is a solid accounting and billing system for calculating the expense and value of leasing and sharing with telecom partners.
In the U.S. wholesale market, that billing and accounting foundation is BillTrack On Demand (BTOD), a TEOCO solution that’s been in place for 25 years and in use by 80% of the carriers in the market.
Now TEOCO is developing new Machine Learning and Computer Vision capabilities to further improve efficiency and bottom line savings for its customers. Here to discuss these moves is Jacob Howell, TEOCO’s Global Director for Machine Learning, Innovation and Implementation.
| Dan Baker, Editor, Black Swan Telecom Journal: Jacob, applying machine learning to wholesale accounting and billing sounds like a great idea. What’s your latest R&D program all about? |
Jacob Howell: Dan, over $20 billion U.S. dollars passes through our BTOD software each month. This is money that’s charged back and forth between carriers here in the U.S. who lease facilities and buy network services from each other on a wholesale basis.
Now GAAP regulations, Generally Accepted Accounting Practices, require that every item on every one of those invoices be accounted for in each carrier’s General Ledger (GL).
Yet for every carrier, that’s a lot of detail to keep track of and account for properly.
The carriers’ challenge is that each month, new interconnect and partner charges are added. Plus, circuits are continually being changed, moved, or disconnected — all of these changes can impact the accuracy of the carriers’ accounting.
When these new billing situations and changes occur, it takes time to ensure that the right GL codes are applied. This requires a degree of manual intervention and is the reason why it generally takes 3 to 4 weeks for a carrier to process its inter-carrier monthly invoices.
The chart below shows you the scale of the GL coding for a Tier 1 Carrier. In a three month period that carrier processed 630 partner invoices and more than 2 million GL entries.

Our system aims to correct these issues. We feed past invoices and examples of charges that the carrier has previously coded to an Artificial Intelligence/ Machine Learning (AI/ML) system that interfaces with our BTOD system. Then the system automatically recommends which accounting code should be used when new charges are flagged or show up in our system.
| OK, so you’re in the process of rolling out machine learning for the many customers in North America who have BillTrack On Demand. What benefits are the early adopters getting from the system? |
Efficiency is the first benefit. Instead of taking weeks to process invoices, it takes only minutes. One carrier who has this ML capability estimates they will save about a quarter million dollars in resource costs per year.
So once this ML capability is rolled out to our full customer base, we estimate it’s going to save our customers tens of millions of dollars per year.
But efficiency is just one side of the story. A more significant benefit is the ability to flag errors and avoid disputes. Let me explain that with a little analogy:

- In the U.S., a software program called TurboTax is a highly popular tool taxpayers
use to figure out how much money they owe to the federal government’s
Internal Revenue Service (IRS).
When it comes time to calculate my previous year’s taxes, I plug my numbers into TurboTax. Then, as a final step, the program scans my entries for errors and other inconsistencies that might, for instance, flag my tax return for an audit by the IRS.
Well, you can think of our new GL coding system as a large scale and highly specialized version of TurboTax. It looks at all the charges that have been coded and flags those that are suspicious — and therefore require a second review.
So the impact of that is there are fewer disputes. Along with that, there are fewer late charges.
Think about that $20 billion figure that passes through our system every month. If those late charges add up to less than one percent-say 0.5%--that’s $1.2 billion a year in bottom line savings. That money is freed up because it doesn’t have to be accrued, thereby increasing liquidity and financial flexibility for our customers.
Here’s the basic architecture of our GL Coding mechanism:
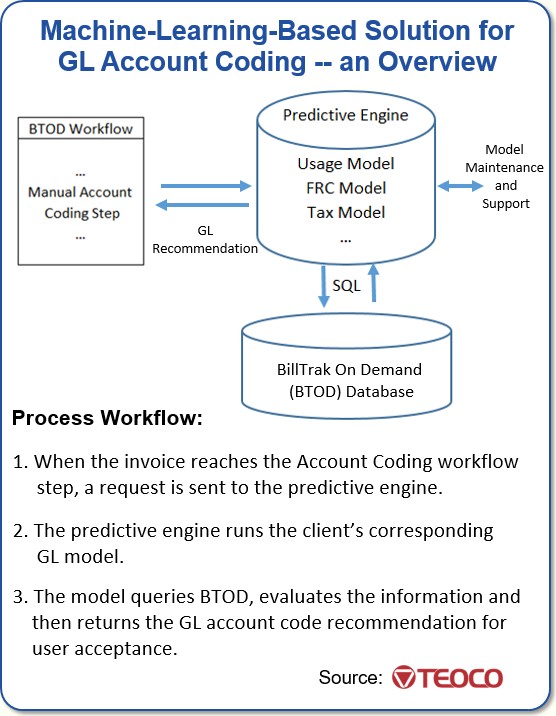
| Does every carrier have its own codes? |
Yes, there’s quite a bit of variation in how each carrier assigns its general ledger codes. And this was a surprise to us.
Some assign it by product so they can figure their costs on a product level. Others track them on a regional basis. There are many methodologies, all of which means we have to tweak our models for each carrier’s unique environment.
So essentially, every carrier has its own classification system. Therefore a single model to support all GL account codes is not feasible. Not only that, each type of charge evaluates different variables and weightings for GL account code predictions.
Finally, our clients periodically change their GL assignments, which requires a quick refreshing of our ML models.
To give you an idea how complex the problem is, here’s a short list of some of the individual charges and attributes we incorporate within our models:
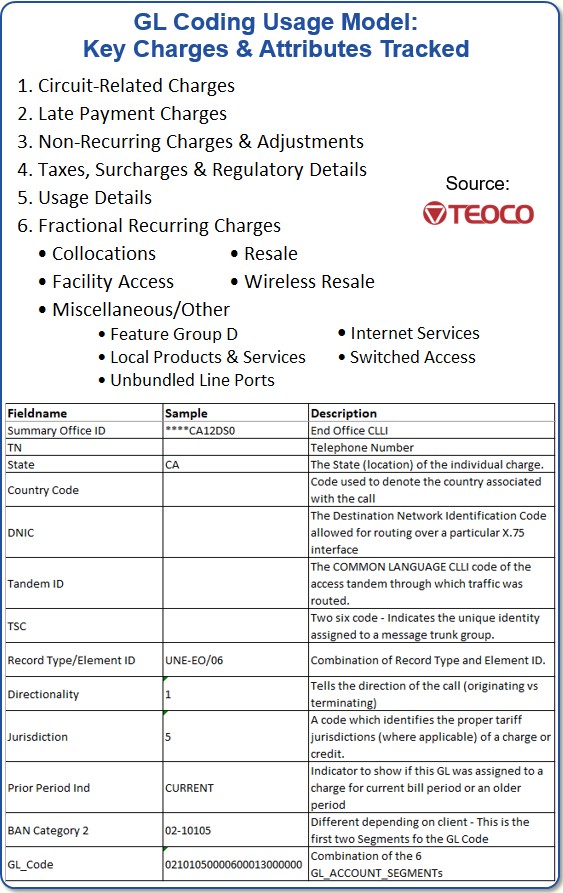
| Will it capture incidents of fraud? I’m thinking of the massive fraud that occurred at WorldCom two decades ago where Bernie Ebbers and his team were caught “cooking the books” on a massive scale. |
It may definitely help. What this system does is make accounting more of a “hands off” process, so it would be much harder for top executives or other insiders to commit accounting fraud.
The GL coding is also being used by audit groups to identify traffic pumping where they see spikes in usage both in the U.S. and international destinations.
| I understand TEOCO is also working on another technology tool for the bill auditing process: something that reads data from inter-carrier contracts. What’s that about? |
It’s a computer vision-driven solution that reads contracts to discover key billing details. The idea is to fully automate the contract-to-bill reconciliation process.

Back in a past life when I did Revenue Assurance, we did a lot of switch-to-bill reconciliations. We would capture call records off the switch and then trace them through to the bill. Then, later on, we would reach further back in time to compare the bill to our ordering and contract information. So contract information is required to do a full reconciliation.
The process today involves auditors receiving a number of scanned copies of partner contracts. It requires quite a bit of effort to read through those contracts and extract relevant billing details. Some of these contracts are quite large — 100 pages or more long!
These contract searches require an enormous amount of time. And to “read between the lines” and truly understand what’s being said requires someone who’s an expert in the process being discussed within the contract.
In the past it took an auditor a full day, or more to manually read contracts and understand the details. However, with this new approach of ours, the average contract can be read and reviewed in only 3 to 4 minutes. Larger PDFs might take up to 7 minutes.
The point is you can save many hours-worth of an auditor’s time.
With one click, our solution opens a contract, reads through the agreement using computer vision and identifies the key billing details and — with the help of OCR — converts those billing details to text and exports the results into an Excel template.
In this way, all the relevant details are combined into a single reference worksheet per contract. We then load these contract reference sheets into our audit database which then feeds many of our downstream automated audit processes.

| What’s the state of deployment of this contract reconciliation aid? |
Right now we’re using the system internally, but we are actively working to make it generally available to our clients.
We haven’t quite figured out how we will roll it out commercially. Should we offer this as a standalone product, or integrate it with some other new products in our pipeline? We’re still deciding that.
Right now, it’s being used to capture information off our clients’ inter-carrier contracts such as between a carrier and a CLEC. But in the future it could be applied to other contracts, say between a carrier and its enterprise customers.
Another challenge we have come across is that carriers don’t necessarily have uniform contracts. Take a big carrier like T-Mobile USA. They’ve acquired Sprint and several other carriers over the years. Each of them had their own written contracts. So we’ve had to do additional training for our models to accommodate all the different variations.
| I can foresee challenges reviewing these contracts because not every table is relevant and OCR scans aren’t 100% accurate. |
Yes, there are many other types of tables in our clients’ contracts. But we can identify particular tables that are relevant to us. And this is done with almost 99.9% accuracy. So that step has become almost foolproof.
However, it’s true: OCR sometimes fails. Even human readings are not always reliable. And there are many reasons for the failure. The contracts may not be legible. Or, maybe it wasn’t scanned correctly.
In our approach we perform additional verifications. For instance, we check to ensure that the OCR’s input matches expected line item charges. However, if there are still issues, the process kicks those documents out for manual review.
The point is: there are multiple validation processes here that serve to double check the results. In our tests with two large U.S. carriers, we have achieved 95% accuracy so far.
| Do you also use natural language processing? Many contract terms are embedded in text and don’t use tables and schedules. |
Yes, we use a system that searches for the date, contract number and many other variables. So in those cases we have to resort to natural language techniques.
For example, suppose in one particular place in the document, a small letter “u” is used; then in another place a capital “U” is used. The program must understand that these uses describe the same entity.
The program we use for the computer vision identifies and analyzes the tables in much the same way as other machine-vision systems use face recognition. It’s very much the same type of algorithm.
So we’ve had to leverage a combination of different technologies to make all this work. We are also leveraging a robotic process automation to coordinate all the different technologies being used.
| Jacob, thanks for this fine briefing. It’s an ambitious upgrade problem, but it sounds like the benefits to the carriers will be pretty extraordinary. Please keep us posted on your progress. |
Copyright 2021 Black Swan Telecom Journal



Jacob Howell is an experienced Revenue Assurance and Fraud Management practitioner with 20+ years of experience working with top wireless, wire line, mobile virtual network operator (MVNO) and VoIP service providers. Drawing on those experiences, he currently leads TEOCO’s Data Science, Robotic Process Automation, Innovation and Implementation groups.
Prior to joining TEOCO, Jacob held management and leadership positions within Disney Mobile, TW Telecom (now Lumen) and XO Communications (now Verizon). While at those companies he was responsible for enhancing Billing Operations, Revenue Assurance, Fraud Management, Network Operations, Credit Management, and Collections and Subpoena Compliance.
He is a Certified Data Scientist, Certified Communications Security Professional (CCSP), Executive Secretary of the Communications Fraud Control Association (CFCA), author the CFCA’s Global Telecom Industry Fraud Loss Survey since 2007, and a popular presenter. Contact Jacob via
Black Swan Solution Guides & Papers
- Expanding the Scope of Revenue Assurance Beyond Switch-to-Bill’s Vision — Araxxe — How Araxxe’s end-to-end revenue assurance complements switch-to-bill RA through telescope RA (external and partner data) and microscope RA (high-definition analysis of complex services like bundling and digital services).
- Lanck Telecom FMS: Voice Fraud Management as a Network Service on Demand — Lanck Telecom — A Guide to a new and unique on-demand network service enabling fraud-risky international voice traffic to be monitored (and either alerted or blocked) as that traffic is routed through a wholesaler on its way to its final destinations.
- SHAKEN / STIR Calling Number Verification & Fraud Alerting — iconectiv — SHAKEN/STIR is the telecom industry’s first step toward reviving trust in business telephony — and has recently launched in the U.S. market. This Solution Guide features commentary from technology leaders at iconetiv, a firm heavily involved in the development of SHAKEN.
- Getting Accurate, Up-to-the-Minute Phone Number Porting History & Carrier-of-Record Data to Verify Identity & Mitigate Account Takeovers — iconectiv — Learn about a recently approved risk intelligence service to receive authoritative and real-time notices of numbers being ported and changes to the carrier-of-record for specific telephone numbers.
- The Value of an Authoritative Database of Global Telephone Numbers — iconectiv — Learn about an authoritative database of allocated numbers and special number ranges in every country of the world. The expert explains how this database adds value to any FMS or fraud analyst team.
- The IPRN Database and its Use in IRSF & Wangiri Fraud Control — Yates Fraud Consulting — The IPRN Database is a powerful new tool for helping control IRSF and Wangiri frauds. The pioneer of the category explains the value and use of the IPRN Database in this 14-page Black Swan Solution Guide.
- A Real-Time Cloud Service to Protect the Enterprise PBX from IRSF Fraud — Oculeus — Learn how a new cloud-based solution developed by Oculeus, any enterprise can protect its PBX from IRSF fraud for as little as $5 a month.
- How Regulators can Lead the Fight Against International Bypass Fraud — LATRO Services — As a regulator in a country infected by SIM box fraud, what can you do to improve the situation? A white paper explains the steps you can and should you take — at the national government level — to better protect your country’s tax revenue, quality of communications, and national infrastructure.
- Telecom Identity Fraud 2020: A 36-Expert Analysis Report from TRI — TRI — TRI releases a new research report on telecom identity fraud and security. Black Swan readers can download a free Executive Summary of the Report.
- The 2021 State of Communications-Related Fraud, Identity Theft & Consumer Protection in the USA — iconectiv — This 49-page free Report on communications-related fraud analyzes the FTC’s annual Sentinel consumer fraud statistics and provides a sweeping view of trends and problem areas. It also gives a cross-industry view of the practices and systems that enable fraud control, identity verification, and security in our “zero trust” digital world.